Feature-Driven Lives Inside DDD. Stop Arguing About It.
Levi Garner
Founder & CTO, InteliG

Every DDD argument on LinkedIn is the same.
Someone posts about Domain-Driven Design. Someone else replies “we use feature-driven architecture instead.” A third person says DDD is “too complex.” Then fifty people argue about folder structures for three days straight.
They’re all wrong. Feature-Driven and DDD aren’t competing approaches. Feature-Driven lives inside DDD. The bounded context IS the boundary. The features ARE the user-centric workflows within it.
I built InteliG across 17 bounded contexts — identity, billing, git, cognis, knowledge, strategy, contributor, finance, and more. Every one of them uses DDD + CQRS. Some use Event Sourcing. Some use feature-driven vertical slices. The choice isn’t DDD or Feature-Driven. It’s which DDD pattern fits the complexity of this specific context.
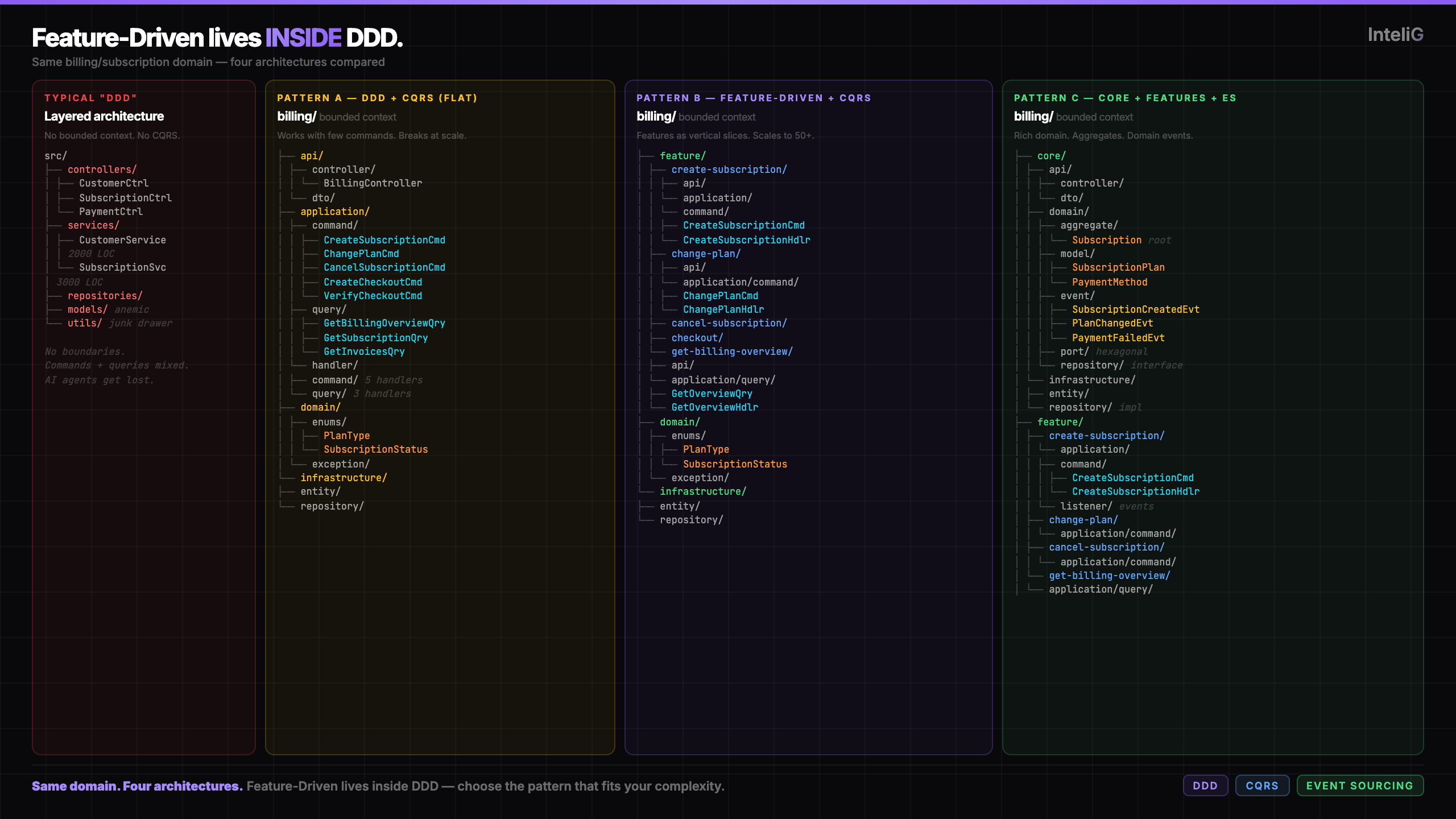
Here’s the same billing/subscription domain sliced four ways. One wrong. Three right.
The Wrong Way: What Most People Call “DDD”
Layered architecture with domain folders. God classes. No real boundaries. This is what most people build when they say they’re “doing DDD.”
src/
├── controllers/
│ ├── CustomerController
│ ├── SubscriptionController
│ └── PaymentController
├── services/
│ ├── CustomerService ← 2000 LOC god class
│ └── SubscriptionService ← 3000 LOC god class
├── repositories/
│ ├── CustomerRepository
│ └── SubscriptionRepository
├── models/ ← anemic data bags
│ ├── Customer
│ └── Subscription
└── utils/ ← the junk drawer
Technical layers as top-level organization. No bounded context boundaries. Services become god classes mixing commands and queries. Models are anemic — no business logic, just getters and setters. Everything touches everything.
And here’s the part nobody talks about: AI agents can’t reason about this structure. They see file types, not intent. They can’t tell you what this system does — only what it’s made of.
The people who “tried DDD and didn’t like it” usually built this. They never did DDD. They did layered architecture and called it DDD because they had a domain/ folder.
Pattern A: DDD + CQRS (Flat)
Bounded context at the top. Clean separation of commands and queries. Domain and infrastructure at the context level.
billing/ ← bounded context
├── api/
│ ├── controller/
│ │ └── BillingController
│ └── dto/
│ ├── command/
│ └── query/
├── application/
│ ├── command/
│ │ ├── CreateSubscriptionCommand
│ │ ├── ChangePlanCommand
│ │ ├── CancelSubscriptionCommand
│ │ ├── CreateCheckoutSessionCommand
│ │ └── VerifyCheckoutSessionCommand
│ ├── query/
│ │ ├── GetBillingOverviewQuery
│ │ ├── GetSubscriptionQuery
│ │ └── GetInvoicesQuery
│ └── handler/
│ ├── command/
│ └── query/
├── domain/
│ ├── enums/
│ └── exception/
└── infrastructure/
├── entity/
└── repository/
This works when the context is small — fewer than 10 commands and queries total. Everything fits in your head. AI agents can scan the full command/ or query/ folder in one shot and understand the scope.
But it breaks down. At 10+ commands, the command/ folder becomes a wall of files. You lose the “what does this context do?” signal. It’s just a list of classes. AI agents scanning handler/command/ see 15 handlers with no grouping, no way to understand which command relates to which use case.
Pattern B: Feature-Driven + CQRS
Same bounded context, but features are the top-level organization inside it. Each feature is a vertical slice that owns its own API, commands, and queries. Domain sits at the context level, shared across features.
billing/ ← bounded context
├── feature/
│ ├── create-subscription/ ← feature (command)
│ │ ├── api/
│ │ │ └── controller/
│ │ └── application/
│ │ └── command/
│ │ ├── CreateSubscriptionCommand
│ │ └── CreateSubscriptionHandler
│ ├── change-plan/ ← feature (command)
│ │ ├── api/
│ │ └── application/
│ │ └── command/
│ ├── cancel-subscription/
│ ├── checkout/
│ └── get-billing-overview/ ← feature (query)
│ ├── api/
│ └── application/
│ └── query/
│ ├── GetBillingOverviewQuery
│ └── GetBillingOverviewHandler
├── domain/
│ ├── enums/
│ └── exception/
└── infrastructure/
├── entity/
└── repository/
This is where it gets interesting. Each feature is a vertical slice — owns its own command OR query, never mixed. Features are isolated. Change one without touching another. AI agents point at change-plan/ and immediately understand scope.
The domain still sits at the context level — shared enums, value objects, exceptions. The features don’t own the domain. They operate within it.
This is Feature-Driven architecture. And it lives inside the bounded context. Not beside it. Not instead of it. Inside it.
Pattern C: Core Domain + Feature-Driven + Event Sourcing
When the bounded context has a rich domain — aggregate roots, domain events, value objects — the features operate ON the domain. The core/ holds the shared domain truth. Features hold the use cases.
billing/ ← bounded context
├── core/ ← shared domain layer
│ ├── domain/
│ │ ├── aggregate/
│ │ │ └── Subscription ← aggregate root
│ │ ├── model/
│ │ │ ├── SubscriptionPlan ← value object
│ │ │ └── PaymentMethod
│ │ ├── event/
│ │ │ ├── SubscriptionCreatedEvent
│ │ │ ├── PlanChangedEvent
│ │ │ └── PaymentFailedEvent
│ │ ├── port/ ← interfaces (hexagonal)
│ │ └── repository/ ← interface only
│ └── infrastructure/
│ ├── entity/
│ ├── mapper/
│ └── repository/ ← implementations
├── feature/
│ ├── create-subscription/
│ │ ├── api/
│ │ └── application/
│ │ ├── command/
│ │ └── listener/ ← reacts to domain events
│ ├── change-plan/
│ │ └── application/
│ │ ├── command/
│ │ └── query/
│ ├── cancel-subscription/
│ └── get-billing-overview/
The core/ owns the aggregate root, domain events, and value objects — pure domain. Features operate ON the core domain. The aggregate root (Subscription) enforces all business invariants. Features can’t bypass it. Domain events drive cross-feature communication. Ports and interfaces live in core, implementations in infrastructure.
AI agents understand this instantly: “core = the truth, features = the actions.”
The Progression Is the Point
| Pattern | When to use | Operations | Domain complexity |
|---|---|---|---|
| A Flat CQRS | Small context | < 10 commands/queries | Low |
| B Feature-Driven | Many operations | 10+ | Low to medium |
| C Core + Features + ES | Rich domain | 10+ | High |
These aren’t competing philosophies. They’re a progression. You choose based on the complexity of your specific bounded context. At InteliG, the identity context uses Pattern A — it’s simple, a handful of commands. The cognis context uses Pattern C — it has aggregate roots, domain events, and complex business rules that span multiple features.
The wrong way isn’t on this chart. It has no bounded context, no CQRS, no domain isolation. It’s what happens when you skip DDD entirely and call it DDD anyway.
Why This Matters for CTOs
If you’re leading an engineering team, the DDD vs. Feature-Driven debate is a distraction. The real question is: can your team navigate the codebase? Can they find what a system does in under 30 seconds? Can an AI agent reason about your code’s intent?
With Pattern A, you can — if the context is small. With Pattern B, you can — because features are self-documenting. With Pattern C, you can — because the domain is explicit and the features are isolated vertical slices.
With the “wrong way,” nobody can. Not your team. Not your AI tools. Not you.
Feature-Driven and DDD aren’t competing. One lives inside the other. The people who “don’t like DDD” usually never did DDD. They did a layered architecture, called it DDD, and got burned.
Stop arguing about folder structures on LinkedIn. Start thinking about bounded contexts, domain complexity, and which pattern fits. That’s the actual job.
See What Your Engineering Org Is Really Doing
InteliG reads your repos, analyzes every commit, and gives you the execution intelligence CTOs actually need.
Start Your Trial