Episode 1: Why Most AI Agents Are Useless
Levi Garner
Founder & CTO, InteliG
The Agent Series. Episode 1 of 4. A 4-part deep dive into AI agents: what they actually are, why most of them fail at engineering execution, and what an intelligence agent looks like running in production. New episodes drop every two weeks.
Watch the Episode
Episode 1 of 4 from my conversation with Sachin Menon on 101 Talks. The written companion below goes deeper than the episode.
The word “agent” is the most expensive marketing victory of the last 18 months.
Two years ago it meant a system that observes a domain, reasons about what it sees, and acts without being told. Today it means whatever the marketing team decided this morning. A ChatGPT plugin. A workflow that fires three API calls. A coding assistant that loops until tests pass. A chatbot with a personality.
These are not the same thing. And calling all of them “agents” is doing real damage. CTOs are paying intelligence-agent prices for task-agent capability. Boards are funding companies whose entire AI story collapses the moment you ask “what does it actually do that’s different from a function call?”
This series is about that gap. Episode 1 is about giving you the language to see it clearly.
The category mistake
A vendor walks in. They demo a product called an “AI agent.” It opens a chat. You type a question. It calls your GitHub API, returns text. The salesperson says it’ll save your team 40 hours a month. The contract is six figures.
Six months later, you check usage. The “agent” has been called twice. Once during onboarding. Once when a curious engineer wanted to see what it did. The system sits idle because, surprise, it doesn’t actually do anything unless someone remembers to type into it. It has no awareness of what changed yesterday. It can’t tell you what needs your attention right now.
It’s not an agent. It’s a UI on top of a function call. You bought it because the word let the vendor describe it that way.
The fault is upstream. We let one word mean four different things and now nobody can tell which one they’re buying.
The four paradigms
There are four kinds of “agents” in the market. They cost different amounts. They unlock different value. They fail at very different things.
Task agents. LLM plus a tool call plus a return value. ChatGPT plugins. Claude with MCP. Anything that fires a single function and returns text. The 99%.
Workflow agents. Multi-step plan, act, observe, adjust. AutoGPT. CrewAI. AutoGen. They can complete tasks, sometimes complex ones, but they’re stateless across sessions. Conversation ends, agent forgets you exist.
Coding agents. Write, run, and debug code autonomously until tests pass. Devin. Cursor. Claude Code. Replit Agent. GitHub Copilot Workspace. Best-in-class technically, but they operate on a codebase, not on understanding the organization that’s building the codebase.
Intelligence agents. Continuously observe a domain. Build internal models. Surface what matters without being asked. Pre-compute understanding so the answer is ready before the question. The closest mainstream comparison is Palantir Foundry. It’s not for engineering. It costs millions per year. The category is essentially empty.
Most “agents” you’ve heard of are categories 1 through 3. The category that turns AI from a productivity feature into infrastructure is category 4. That’s the gap we’re building into.
Why intelligence is the only category that matters for execution
Task agents are useful for tasks. Coding agents are useful for code. If you have a well-defined unit of work like “summarize this PR” or “fix this failing test,” they do it. That’s real value, especially for individual developers.
But running an organization requires something different. It requires a system that understands the domain over time. Observes continuously. Remembers what it noticed yesterday. Sees patterns across hundreds of signals and surfaces the ones that matter.
A task agent can ship a feature. It cannot tell you whether your team should ship that feature. A coding agent can write the code. It cannot tell you who’s quietly carrying the team, who’s checking out, or which initiative is silently drifting because three of its commits got rejected last sprint.
For execution intelligence, the first three categories are insufficient by design. You need category 4. Almost no one has built it.
I built a test for this
I got tired of arguing about which products are “real” agents. So I built a 20-point rubric. Four traits. Each scored 0–5.
The full rubric, the entire competitor scorecard, and Cognis’s honest self-score with code citations are at /blog/the-intelligence-agent-test/.
The summary: the field of “agents” you’ve heard of scores between 1 and 5 out of 20. ChatGPT, Devin, Cursor, AutoGPT, all under 6. Engineering analytics tools (LinearB, Jellyfish, Cortex) also under 6, because they’re not agents at all. They’re metric dashboards. Cognis sits at 11/20 today and is on a roadmap to 17 by Q4. The gap between 5 and 11 isn’t a feature gap. It’s an architectural gap.
What this actually looks like
Here’s a real Cognis answer. CTO question: “What was our most impactful commit this quarter, and why?”
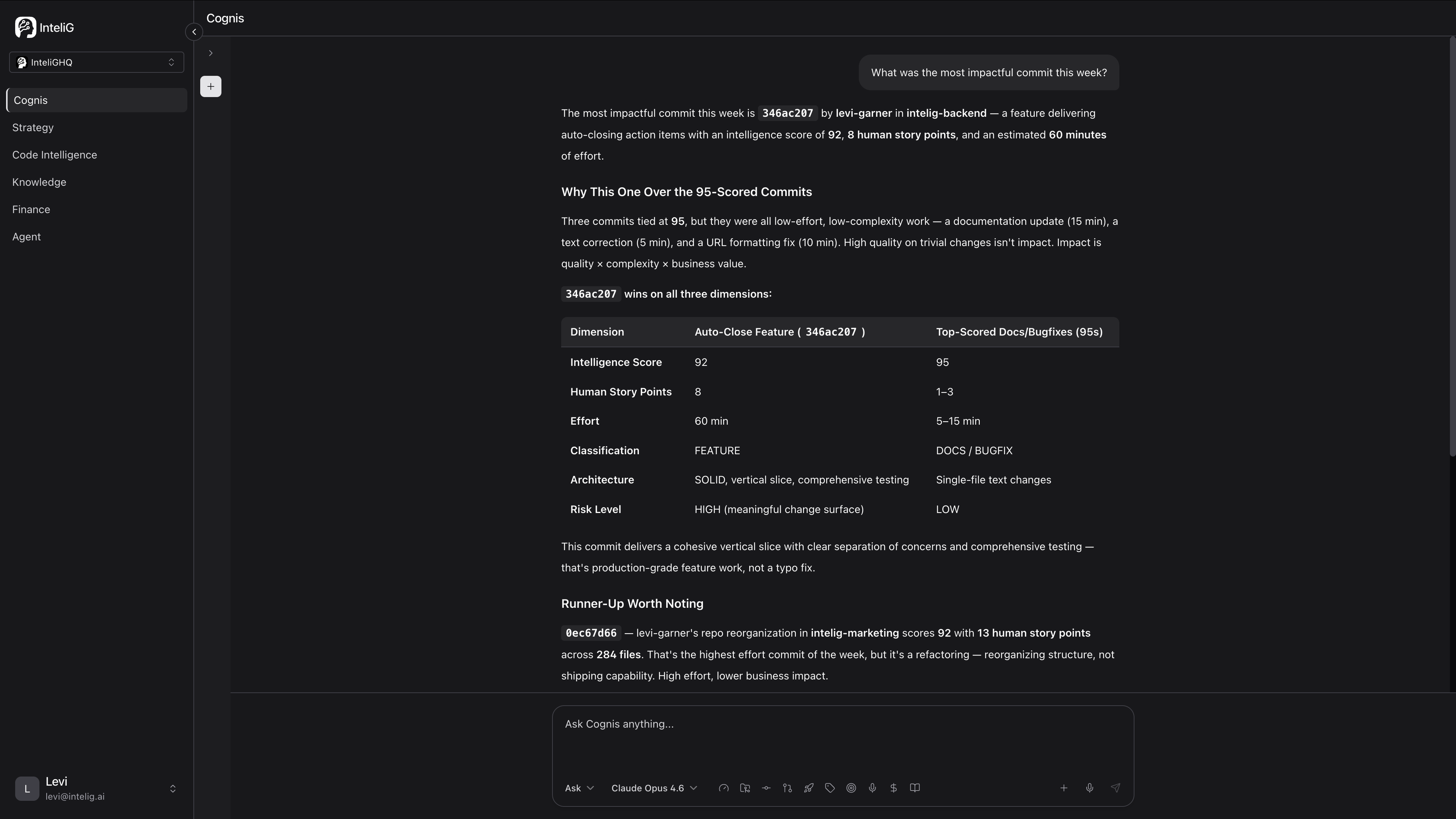
This isn’t a chat answer reasoned from scratch. It’s the system retrieving understanding it built continuously while nobody was looking. The commit was scored when it landed. The contributor was already profiled. The initiative was already linked. The cost was already attributed. By the time the CTO asked, the answer existed.
That’s the difference between a system that thinks when you prompt it and a system that has been thinking the whole time.
The architectural unlock
Here’s the conceptual key, and it’s the same key that explains why the entire field is stuck below 6.
Take Claude, the best general-purpose LLM in the world, and ask it about your engineering org. It’ll hallucinate, hedge, or give you a generic answer.
Now give Claude a MEMORY.md file with persistent context about your team, your codebase, your priorities. Run the same conversation. Suddenly the same model is reliable. It cites specifics. It feels like an expert.
Same model. Same prompt. The only thing that changed was persistent memory.
This is the entire game. The reason every “agent” in the field scores under 6 is the same reason a stateless LLM is unreliable for any specific domain: it has no memory, so it has no understanding to compound. Every conversation is the first conversation. Every insight is forgotten the moment the session ends.
The fix isn’t a smarter model. The fix is persistent memory plus continuous observation. A system that’s awake when you’re not, watching, extracting findings, writing them somewhere durable, and pulling them back into the next reasoning pass. That’s the architecture of Cognis. That’s the architecture almost nobody else is shipping.
If I were starting a company today
I build with Claude. Not Cursor. Not Devin. Not GitHub Copilot Workspace. Claude Code in the terminal, Claude API in the agents I orchestrate, Claude on the desktop when I think. Ten to twelve hours a day, every day, for the last two years.
This isn’t brand preference. It’s an architectural choice.
Devin and Cursor are trying to be the agent. They wrap a model in an opinionated UI, decide for you how the loop runs, ship the whole package. When the underlying model improves, you wait for them to update. When you want different behavior, you fight their abstractions. They cap out around 3 on the IAT because the architecture is wrong for compounding intelligence.
Claude is different. It’s the reasoning core you orchestrate. You decide the loop. You decide the memory model. You decide what tools it has. The model is the most capable on the market for serious engineering work, and you don’t pay a tax for someone else’s UI to wrap it.
If I were a CTO starting a company today, the foundation would be two things. Claude for the leverage. InteliG for the intelligence. Claude does the work: code, refactoring, docs, agent orchestration. InteliG understands what got done: the execution graph, the contributor patterns, the initiative alignment, the cost. One generates output. The other comprehends it. Together they compound.
A solo CTO with that stack today has more leverage than a 30-engineer org running on Cursor plus Jira plus LinearB in 2024. That’s not hyperbole. That’s the IAT scorecard playing out at the org level.
The dashboard era is over. The wrapper-products era is next.
What’s coming in the rest of the series
- Episode 2: The architecture. Exactly how Cognis works today. The reasoning loop. The Knowledge Store. The background scheduler. What 11/20 looks like in production code.
- Episode 3: The leap. Live demo of the features that close the gap to 17. Cognis Operator. Intelligence Feed. Dynamic Greeting. The system observing and surfacing without prompts.
- Episode 4: The vision. Closed-loop intelligence. The end of Jira-driven engineering. Systems that don’t just observe but act.
If you want the framework to evaluate what you’re seeing, score your current stack against the IAT before Episode 2 drops. If you want to see what 11/20 looks like running today, book a Cognis demo. I’ll score your current tools on the call. Honestly. With code citations.
The dashboard era is over. The wrapper-products era is next. Time to demand the real thing.
See What Your Engineering Org Is Really Doing
InteliG reads your repos, analyzes every commit, and gives you the execution intelligence CTOs actually need.
Start Your Trial